通过训练自己的神经网络对数据进行分类
注意
我最初用西班牙语写了这篇文章。所以一些资源和代码的引用是用西班牙语的。
介绍
神经网络可以被输入大量的数据。在处理这些数据时,网络允许我们对信息进行分类和回归。在这篇文章中,我们将给神经网络输入信息,然后用它来基于所使用的数据进行估计。
举个例子,我们将使用一个正方形。假设我们有一个1000 x 1000的正方形,其中 0,0 是左上角,1000,1000 是右下角。我们将使用这个名为 coordenadas.json 的 .json 文件,它包含41个坐标块,定义了正方形中的一个点及其描述。我们的目标是将这些信息输入神经网络,然后给它传递其他不在 .json 中的值,让它对坐标是属于正方形的左上、左下、右上还是右下进行分类。
要求
要进行本教程,我们需要:
文件创建
我们创建一个文件夹并放置以下文件:
recursos/
index.html
index.js
在recursos/文件夹中,我们将放置coordenadas.json文件。
在index.html文件中,我们放入以下代码,基本上是在head中引入ml5.js库。
<html>
<head>
<meta charset="UTF-8" />
<title>通过训练自己的神经网络对数据进行分类</title>
<script src="https://unpkg.com/ml5@0.4.3/dist/ml5.min.js"></script>
</head>
<body>
<script src="index.js"></script>
</body>
</html>在index.js文件中,我们放入以下内容(代码在注释中解释):
window.onload = () => {
/**
* 神经网络选项
* dataUrl: 我们的数据所在的.json文件的url。
* task: 在网络中执行的任务类型,在本例中我们将使用'classification'。
* inputs: 输入数据,即用于给网络喂数据的数据源。
* outputs: 输出数据,即输入数据的描述。
* debug:定义是否在html中显示神经网络训练的可视化。
*/
const options = {
dataUrl: 'recursos/coordenadas.json',
task: 'classification',
inputs: ['x', 'y'],
outputs: ['label'],
debug: true,
};
// 初始化神经网络
const nn = ml5.neuralNetwork(options, normalize);
// 规范化数据
function normalize() {
nn.normalizeData();
train();
}
// 训练数据模型
function train() {
/**
* epochs:就神经网络而言,一个 "epoch"指的是在训练数据上完成一个完整的循环。
* batchSize:信息将被处理的数据块。
*
* 对所需的epochs数量没有具体的规定,但可以根据结果进行测试,找到最佳数量。
*/
const trainigOptions = {
epochs: 250,
batchSize: 12,
};
nn.train(trainigOptions, classify);
}
// 一旦我们的神经网络训练完毕,我们就开始测试它对未知数据的反应。
function classify() {
// 在本例中,我们传递的坐标是300,350,对应于左下角。
const input = {
x: 300,
y: 350,
};
nn.classify(input, handleResults);
}
function handleResults(error, results) {
// 如果有错误,我们将其放入控制台
if (error) {
console.log(error);
return;
// 如果一切成功,我们可以在浏览器控制台看到执行分类的结果。
} else {
console.log(results);
}
}
};代码执行
我们安装一个名为serve的轻量级服务器。打开命令控制台并输入:
npm install -g serve然后,一旦安装了serve,在项目文件夹中打开控制台并输入:
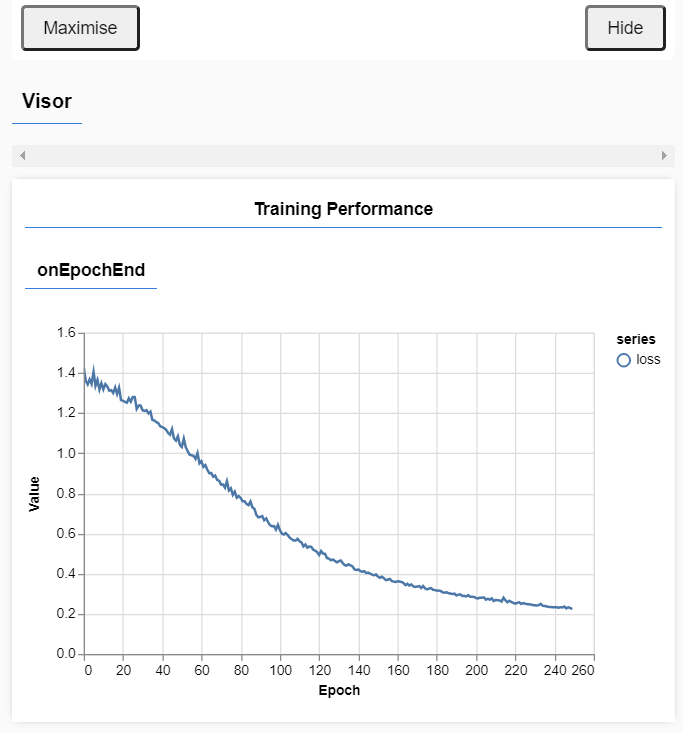
serve默认情况下,这将创建一个在http://localhost:5000上运行的简单服务器。通过导航到这个url,我们可以打开浏览器的开发者工具,并在我们的神经网络中观察数据处理的过程。执行本练习时,我们可以看到类似这样的图表:
在控制台中得到大致如下的结果:
[
{ label: 'izquierda-superior', confidence: 0.8469865322113037 },
{ label: 'izquierda-inferior', confidence: 0.09941432625055313 },
{ label: 'derecha-superior', confidence: 0.0454748310148716 },
{ label: 'derecha-inferior', confidence: 0.008124231360852718 },
];我们可以看到,神经网络成功地将坐标分类为左上角,置信度为0.847或84.7%。我们可以用不同的坐标进行测试,看看神经网络基于它所喂入的数据做出的估计是否仍然准确。
测试 { x: 800, y: 150 }:
[
{ label: 'derecha-superior', confidence: 0.9378078579902649 },
{ label: 'izquierda-superior', confidence: 0.05480305105447769 },
{ label: 'derecha-inferior', confidence: 0.007157310843467712 },
{ label: 'izquierda-inferior', confidence: 0.0002319106279173866 },
];根据结果,我们可以观察到分类再次成功,对于右上角的置信度为93%。
通过这些例子,我们可以一瞥神经网络在基于用于训练它的数据对未知信息进行分类方面的潜力。